On the role of the action space in robot manipulation learning and sim-to-real transfer
How choosing the right action can impact your robot-learning task

Introduction
In recent years, reinforcement learning (RL) has shown great promise in making robots learn complex tasks. But how do you do that? We find that model-free RL, in which no model of the controlled system is assumed, often suffers from sample inefficiency, and exploration (and thus learning) is difficult since we don't know how to safely control the robot. This makes learning on a real system difficult, risky and expensive. The solution that is normally used is to learn robot skills in simulation, where you can't break anything, and then transfer the result to hardware.
Works? Well, yes and no. This approach is hampered by the "sim-to-real gap", because simulation and the real world are never the same. It's a heavily researched area, but to date using policies learned in the simulation to the real world remains challenging, at the least.
Most previous studies focussed on the state and observation spaces and perception aspects of robot policy learning and sim-to-real transfer.
Our goal in the study was to understand the action space and control aspects of this problem. As we found, the choice of the optimal action space – i.e., do we control in joint torques? or Cartesian space? or velocities? etc. – is essential, as it can profoundly influence the learning dynamics in simulation and the system's real-world performance. To investigate this, we posed three primary research questions:
- How does the choice of the action space influence learning and exploration in simulation?
- What is the sim-to-real gap created by different action spaces?
- Are there action spaces that improve or hinder sim-to-real policy transfer?
In our large-scale study, we evaluated 13 different action spaces across two robotic tasks, namely reaching and pushing. We show that the choice of action space can have a large impact on how well policies transfer to the real world.
We categorised these action spaces into two primary types: joint space action spaces and configuration space action spaces.
Besides testing torque control, the general idea is to have a policy that outputs either position or velocity targets for the robot's joints or end-effector. Below that we use a low-level impedance controller to go from the policy output to a torque command.
We additionally test common variations of this scheme, namely delta action spaces, where the policy outputs a delta value that is added to the current position or velocity.
For further details and a mathematical description of the action spaces studied we refer you directly to our paper.
Experiments
To evaluate the impact of different action spaces on the performance of reinforcement learning policies in both simulated and real environments, we used two fundamental robot tasks: reaching and pushing.
In the reaching task, the robot must move its end-effector to a random goal. This task helps us assess the precision and responsiveness of various action spaces in the absence of interaction with the environment.
In the pushing task, the robot must push a wooden box from a random starting point on a table to some goal. This task brings additional complexity and dynamics, allowing us to explore how different action spaces handle physical interactions with external objects. The title image of this post shows the pushing setup for a clearer understanding.bb
We used several metrics to analyse the learning process and the sim-to-real transfer for these tasks:
- Episodic Reward: Tracks the effectiveness of the policy during training by measuring cumulative rewards received in each episode. We use this metric to quantify the effectiveness of an action space during learning.
- Offline Trajectory Error (OTE): Measures the discrepancy between joint positions when applying identical action sequences in both simulation and real environments. This metric quantifies the sim-to-real gap introduced by different action spaces.
- Success Rate: We compare the success rates of accomplishing the task in the simulation versus the real world.
In the paper, we present additional metrics, like task accuracy or constraint violation rate, that give deeper insights into the advantages and disadvantages of different action spaces. Collectively, these metrics provide a comprehensive picture of how various action spaces affect the learning efficiency, sim-to-real transferability, and task performance of RL policies in key robotic applications.
To perform the study, we trained more than 20,000 agents in simulation and tested more than 1500 agents on the real-world setup. ,We use Isaac Sim to learn PPO policies in 30 and 120 minutes for the two tasks respectively. The two videos show the training process as well as the evaluation of policies for the pushing task on the real-world robot setup.
Simulation Results
Our study gives insights into the role of action spaces in robot reinforcement learning and sim-to-real transfer. Below, we summarise some key findings from our experiments.
| The learning curves for both tasks and all 13 action spaces are sorted according to their base action spaces. In all figures and tables, the labels J and C stand for joint and Cartesian action spaces, respectively. The symbols P, V, and T denote position, velocity, and torque control, while OI and MI represent two different delta action space schemes, which are detailed in the paper. |
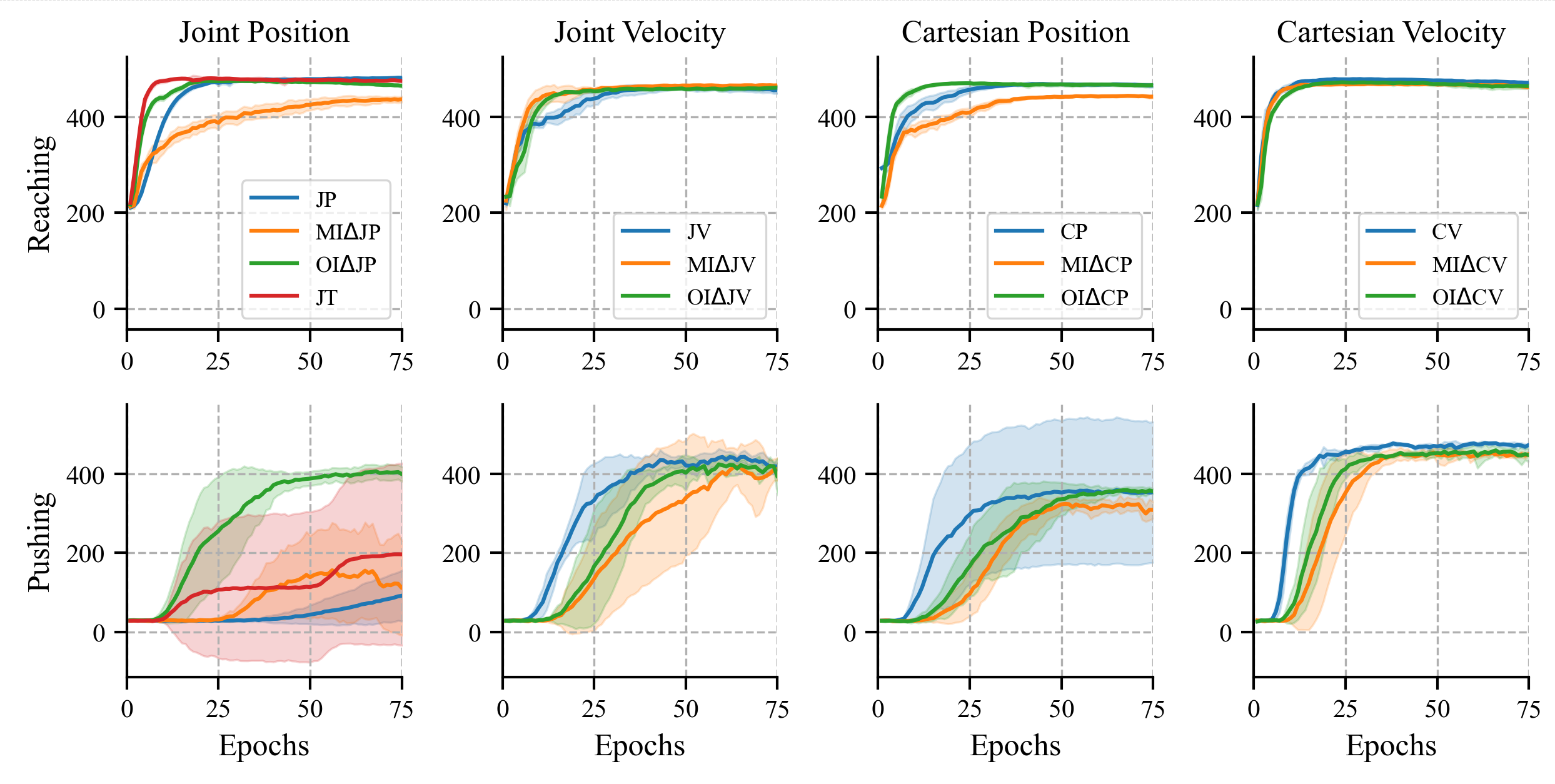
In terms of learning performance, all action spaces showed good learning performance for the reaching task; this is shown in the above figure.
In the pushing task, the learning performance between action spaces differed. Cartesian action spaces mostly outperformed the corresponding joint action spaces. We hypothesise that one reason might be the task being defined in Cartesian coordinates, making the learning process more straightforward for an agent operating directly in this space.
Additionally, velocity-based action spaces consistently outperformed position-based action spaces, regardless of whether the action space was Cartesian or joint. These findings are shown below.

Sim-to-real transfer
| Action Space | Reach: SR (Sim) | Reach: SR (Real) | Reach: OTE [rad] | Push: SR (Sim) | Push: SR (Real) |
|---|---|---|---|---|---|
| JP | 100 | 6 | 0.22 | 87 | 4 |
| JV | 100 | 100 | 0.03 | 97 | 90 |
| JT | 100 | 64 | 0.52 | 40 | - |
| CP | 99 | 25 | 0.16 | 100 | 57 |
| CV | 100 | 43 | 0.35 | 99 | 73 |
Table: Sim-to-real transfer evaluation for various action spaces. Reaching and pushing tasks are evaluated based on success rates (SR) in simulation and real environments, and Offline Trajectory Error (OTE) for the reaching task. J = joint, C = Cartesian; P = position, V = velocity, T = torque.
The table above shows some key results from our study indicating that the choice of action space significantly influences the sim-to-real transferability. This is quantified by the Offline Trajectory Error (OTE) and the success rates. The OTE shows that the action space indeed contributes to the sim-to-real gap. Joint torque control leads to the largest gap, which is maybe intuitive as it is the only action space without additional feedback loops. This makes it more susceptible to discrepancies in robot dynamics between simulation and reality. On the other hand, we found that feedback loops aren't always beneficial. Cartesian action spaces have a higher OTE than joint action spaces because minor changes in dynamics can disrupt the Jacobian, which is crucial in Cartesian control spaces. A key takeaway is that only well-calibrated, highly reactive feedback loops that behave consistently in both simulation and real environments reduce the sim-to-real gap.
When examining success rates, we found that, with the exception of joint torque control, all action spaces showed high success rates in simulation. However, this success did not consistently translate to the real world. Velocity action spaces generally are easier to transfer compared to their position-based counterparts. In the paper we also evaluate how delta action spaces affect the sim-to-real transfer.
Now the interesting question is whether we can predict successful transfer from simulation results alone. This remains a challenging task, however, one promising metric we identified is the Normalized Tracking Error (NTE), which evaluates how accurately the system follows the policy-directed actions:
The NTE measures the distance between the desired target \(v_{d,t}\) given by the policy and the system state at the next time step \(v_{t+1}\). Close tracking generally indicates better transfer potential, as shown below of success rates in simulation and real environments versus NTE for the base action spaces.
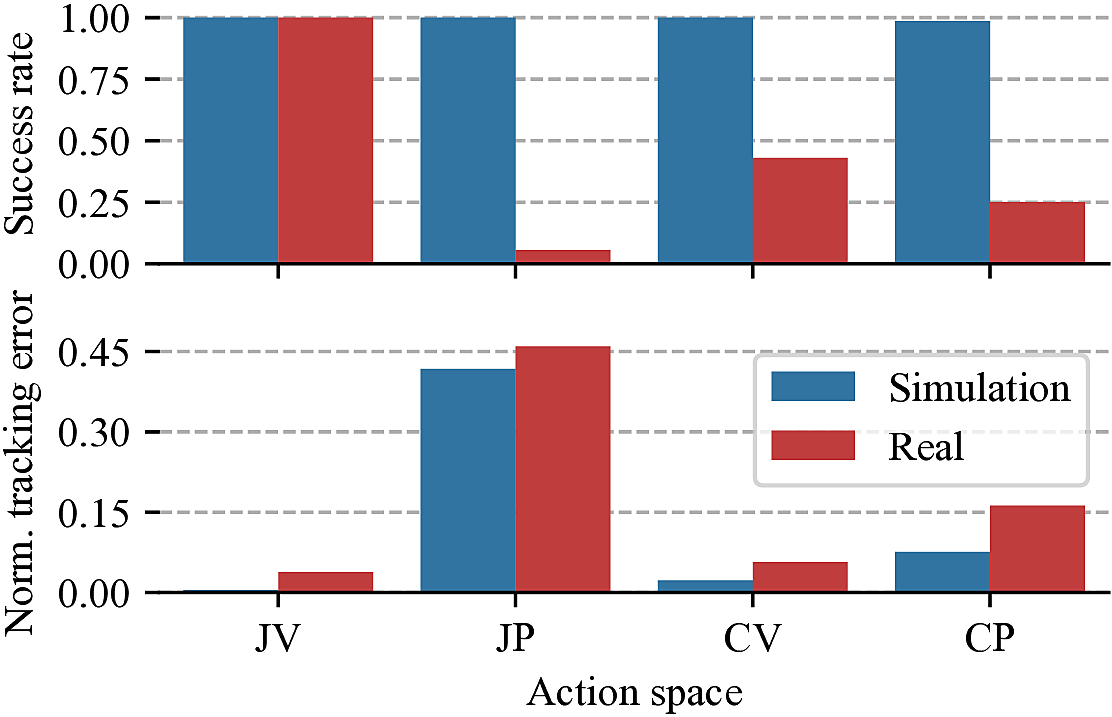
Our findings conclude that the choice of action space can have considerable impact on your results, and you should carefully consider what action space is the correct one when designing your next robot-learning task.
We find that joint velocity action spaces consistently outperformed all other action spaces, making it a strong candidate to consider trying first.
Paper available here:

