Action Inference by Maximising Evidence
Zero-Shot Imitation from Observation with World Models
We always face new challenges, whether travelling to a foreign country, learning a new sport, or simply by using new tools or learning a new technology. A swift way of doing so is by watching someone else and thus learn a basic set of skills, from which that skill can be refined. By observing those who have already mastered the domain, we can gain invaluable insights, imitate their techniques, and learn faster.
We want to take this to robotics. Can we make our artificial agent learn by observing others? In our recent paper (Zhang et al., 2023), we propose a novel algorithm called AIME to achieve observational learning with world models. The following blog post will briefly introduce you the algorithm and highlight the key result.
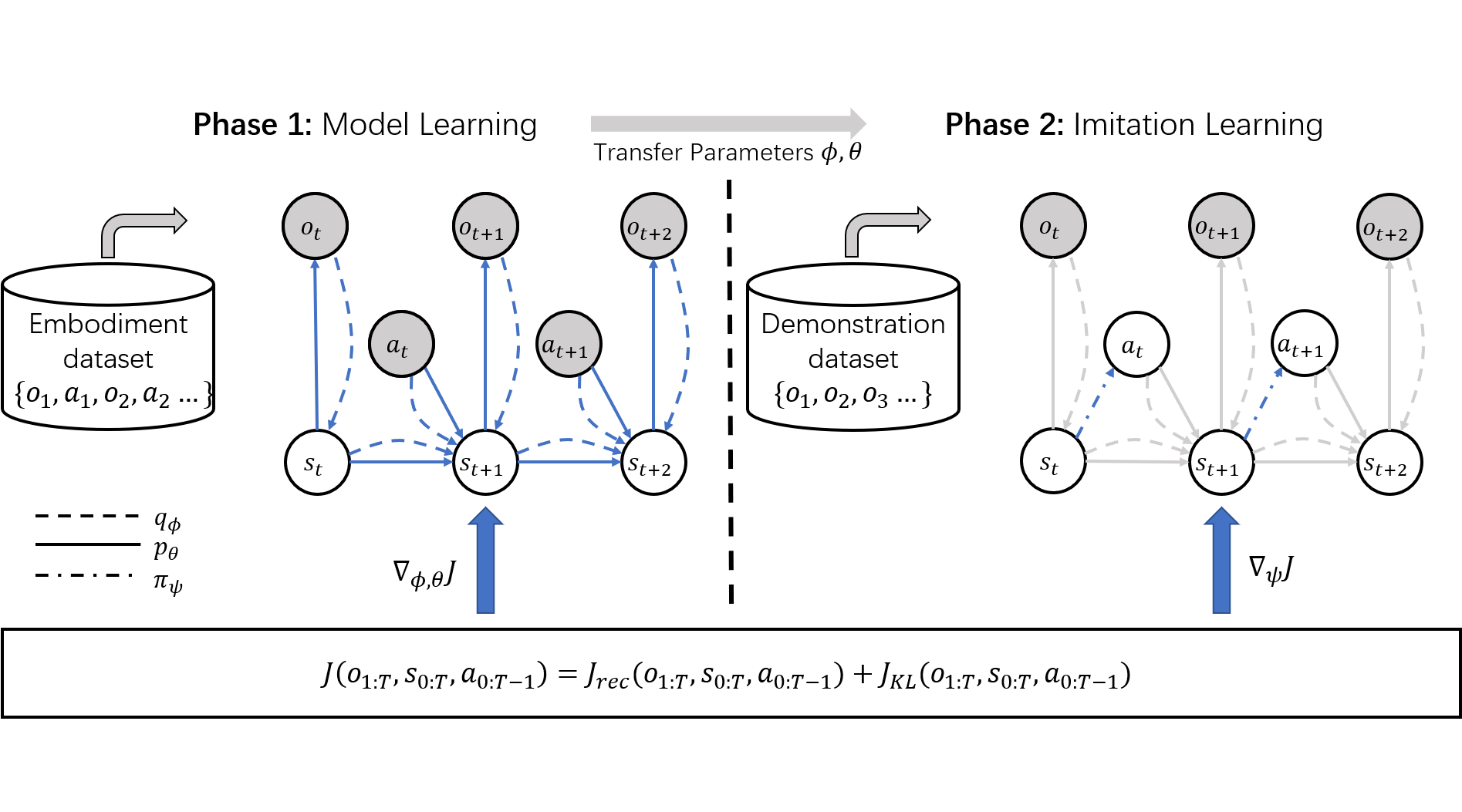
Model Learning
Learning never comes for free. In order to imitate the behaviour from the observation, the agent first needs to understand the embodiment and the observations, especially to understand what behaviour leads to which observation.
One promising way to learn and store this knowledge is pretraining a world model on a diverse dataset from the target embodiment. A world model we considered in this paper consists of four components, namely
These four components can be trained jointly with the ELBO objective, i.e.
Remember, ELBO is a lower bound of the evidence \(\log p_\theta(o_{1:T} | a_{0:T-1})\). Therefore, by maximising the ELBO, the world model is maximising the evidence, and by maximising the evidence, the world model learns to give a higher likelihood to the associated observations and actions; and a lower likelihood otherwise, i.e. understanding the cause and effect of the embodiment dynamics.
Imitation Learning
Now we have the knowledge of the embodiment with the pretrained world model. The next question is, how we can use this knowledge to do imitation or to infer the missing actions? Maybe surprisingly, the imitation can be archived by only slightly modifying the sampling path of model learning objective, that is
Here, \(\psi\) is the parameter of the behaviour model, i.e. the policy. So what did we actually change? During model learning, both the observations and actions are available in the dataset, so both of them are sampled from the dataset, and only the states are inferred. However, when doing imitation learning, the agent only has the access to the observations. Thus, in order to compute the ELBO, both actions and states need to be inferred. By optimising the ELBO with a frozen world model, you learn to infer the unknown actions from the observation; and if the inference model is the policy, you are doing imitation learning!
To understand the method more intuitively, during imitation, the agent is trying to find the policy that makes the behaviour most likely to happen, assuming the model it has of the world. Please read our paper for a detailed derivation of the imitation objective.
Results
We evaluate our algorithm on the DeepMind Control Suite, specially on Walker and Cheetah embodiments where multiple tasks are studied in the literature. Below we show the visualisation of the learned behaviour together with the expert behaviour that we try to imitate. As we can see, AIME can reliably imitate the expert behaviour while the baseline BCO mostly can't. Please find more results in our paper.
| Task | Expert | BCO | AIME |
|---|---|---|---|
| Stand |  |
 |
 |
| Walk |  |
 |
 |
| Run |  |
 |
 |
What's next?
So far we show how a pretrained world model of the embodiment can enable imitation learning by simply modifying the sampling path of the action. That's already very cool! But does that gives us the same ability of observational learning that biologicl systems show? The answer is, of course, no.
In this paper, we only tackle the simple setting where both the embodiment and sensor layout are fixed across tasks. On the other hand, humans observe others in a third-person perspective and can also imitate animals which have a very different body. Relaxing these assumptions will open up possibilities to transfer across different embodiments and enable robots directly imitating from human videos, which open the possibility of learning from billions of human videos on the Internet for our robots.
Moreover, for some tasks, even humans cannot achieve zero-shot imitation by only watching others. This may be due to the task complexity or completely unfamiliar skills. So, even with proper instruction, humans still need to practise in the environment and learn something new to solve some tasks. This motivates an online learning phase 3 as an extension to our framework.
Bibliography
Xingyuan Zhang, Philip Becker-Ehmck, Patrick van der Smagt, and Maximilian Karl. Action inference by maximising evidence: zero-shot imitation from observation with world models. In Conference on Neural Information Processing Systems (NeurIPS). 2023. URL: https://openreview.net/forum?id=WjlCQxpuxU. ↩