How to Learn Functions on Sets with Neural Networks
And how to choose your aggregation
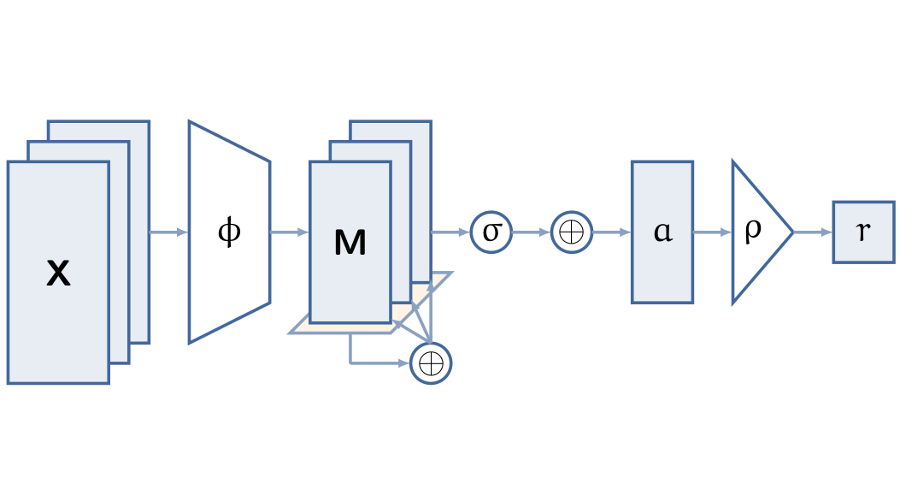
In this post we look into functions on sets, and how to learn them with the help of neural networks. As it turns out, set-valued inputs pose unique challenges to our neural architectures, so let us begin by trying to understand the fundamental differences.
In your common machine-learning task, you are given a data set \(\mathcal D\). Your data set may contain pairs of inputs \(x_i \in \mathcal X\) and outputs \(y_i \in \mathcal Y\). Part of the popularity of neural networks is that they excel in adapting to a huge variety of input domains \(\mathcal X\). In this, there is an implicit assumption so common that we hardly question it in a generic neural application: all inputs \(x_i\) should have the same fixed size, e.g., a vector from some space \(\mathbb R^d\).
Set-valued inputs do not allow for that. Each input is a set—which we will call population. The elements of a population—its particles—have a fixed size, but the entire population size may vary. Feed-forward neural networks, expecting fixed-size input, are not equipped for this task.
There is, however, a class of neural networks than can handle variable-length inputs: recurrent nets. By interpreting a population as a sequence of particles, we could make use of RNNs to process set-valued. Unfortunately, this ignores a fundamental property of sets: they are unordered. To process them with RNNs, we have to impose some (likely arbitrary) order on the set. As Vinyals et al. (2015) have shown, the output of the RNN is highly dependent on the order of inputs. This is undesirable for proper functions on sets.
In short, we are looking for a learnable architecture that
- is able to process input populations of variable size, and
- produces outputs invariant to any particular order of the particles in the population.
Interestingly, it has been shown (Zaheer et al. (2017), refined by Wagstaff et al. (2019)) that a set function \(f\), under mild assumptions, can be decomposed as
Let us take this apart. Any invariant function can be constructed using the same simple recipe: embed each particle individually with \(\phi\), aggregate the embeddings into an invariant, fixed-size description of the set by summing the embeddings, and then process the aggregate description with \(\rho\). The generic architecture is depicted below:
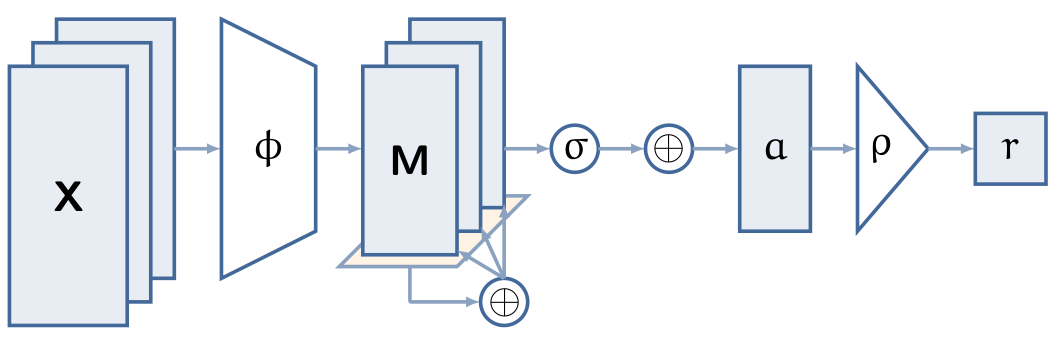
In this formulation, neither \(\phi\) nor \(\rho\) operate on a set. This immediately allows us to plug in function approximators like neural networks for both—a neural architecture that is invariant by design, the Deep Sets framework.
Let us take a closer look at the aggregation step. It is interesting from at least two perspectives: on the one hand, it is the crucial step for inducing invariance to any ordering of the particles in the population. The summation negates the identities of individual particles. On the other hand, despite its importance, and despite seeing alternatives like mean or max being used instead of summation in the literature, it is the only non-learnable part in the Deep Sets framework.
Our Contributions
In our paper On Deep Set Learning and the Choice of Aggregations (Soelch et al., 2019), we examine its role in more depth.
On the theoretical side, we show that a broader class of aggregation functions are also applicable without breaking the theoretical decomposition result, for example mean or also logsumexp. We call this class of functions sum-isomorphic, because they act like a sum in a space isomorphic to \(\mathcal X\). This is interesting because they are numerically favorable over sum: their result does not scale linearly with the number of set elements. For mean aggregations, the activation will be on the same order of magnitude across any population size. A particular case can be made for logsumexp, as it exhibits diminishing returns: the gain from an additional particle diminishes with increasing population size. Moreover, depending on the scale of inputs, logsumexp can behave more like a linear function (for smaller values) or like max (for larger values).
Moreover, we suggest recurrent, learnable aggregations, an aggregation function inspired by the architecture suggested by Vinyals et al. (2015). The idea is to learn an aggregation that dynamically queries the particle embeddings. Each subsequent query \(q_t\) depends on the response \(a_{t-1}\) of the embeddings to the previous query \(q_{t-1}\). This procedure is depicted below.
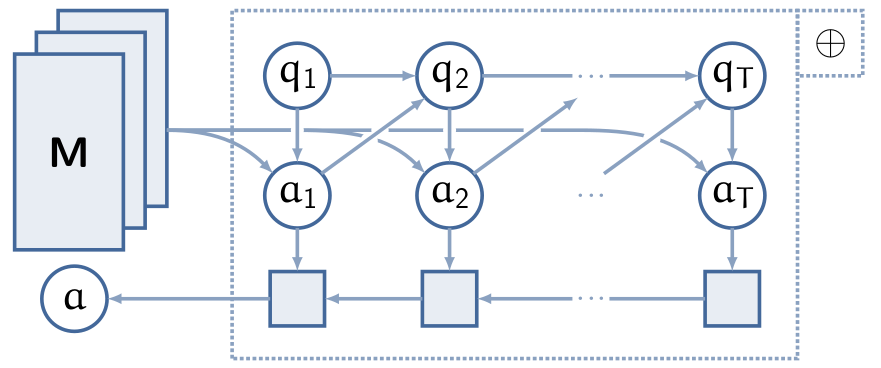
Since each query-response cycle is invariant, the overall procedure is invariant. Lastly, we process all responses in backward order, so that the first query and its response have the most immediate effect on the result of the recurrent aggregation.
On the empirical side, across a number of different experiments, we find a number of interesting results to be considered in future experiments on set-valued inputs:
- Aggregation functions matter: the choice of aggregation function, even if not learned, can have a crucial impact on the overall performance.
- The application matters: which aggregation function to use largely depends on the task at hand. As a general guideline, we found that classification tasks benefit from using max-aggregation, while smoother aggregations tended to work significantly better for regression tasks.
- The population size is understudied: for simplicity, Deep Sets networks are often trained with a fixed population size. We found that this can lead to overfitting for populations of that particular size, and much decreased performance for both smaller and larger populations. In a typical application, where the population size may vary at inference time, a more desired behavior would be a monotonic increase of performance in the population size, akin to asymptotic consistency of statistical estimators.
- Learnable aggregations can make your model more robust to such effects.
We are only beginning to understand the design and learning process of neural set architectures. Our paper will help you selecting appropriate aggregation functions by offering a wider selection of applicable aggregations and empirical results to inform the decision.
This work was published at the International Conference on Artificial Neural Networks (ICANN), 2019, in Munich. We refer to the paper for a more detailed discussion: DOI, preprint.
Bibliography
Maximilian Soelch, Adnan Akhundov, Patrick van der Smagt, and Justin Bayer. On Deep Set Learning and the Choice of Aggregations. In Igor V. Tetko, Věra Kůrková, Pavel Karpov, and Fabian Theis, editors, Artificial Neural Networks and Machine Learning – ICANN 2019: Theoretical Neural Computation, Lecture Notes in Computer Science, 444–457. Springer International Publishing, 2019. URL: https://arxiv.org/abs/1903.07348. ↩
Oriol Vinyals, Samy Bengio, and Manjunath Kudlur. Order Matters: Sequence to sequence for sets. arXiv:1511.06391 [cs, stat], November 2015. URL: http://arxiv.org/abs/1511.06391, arXiv:1511.06391. ↩ 1 2
Edward Wagstaff, Fabian B. Fuchs, Martin Engelcke, Ingmar Posner, and Michael Osborne. On the Limitations of Representing Functions on Sets. arXiv:1901.09006 [cs, stat], January 2019. URL: http://arxiv.org/abs/1901.09006, arXiv:1901.09006. ↩
Manzil Zaheer, Satwik Kottur, Siamak Ravanbakhsh, Barnabas Poczos, Ruslan R Salakhutdinov, and Alexander J Smola. Deep Sets. In I. Guyon, U. V. Luxburg, S. Bengio, H. Wallach, R. Fergus, S. Vishwanathan, and R. Garnett, editors, Advances in Neural Information Processing Systems 30, pages 3391–3401. Curran Associates, Inc., 2017. URL: http://papers.nips.cc/paper/6931-deep-sets.pdf. ↩