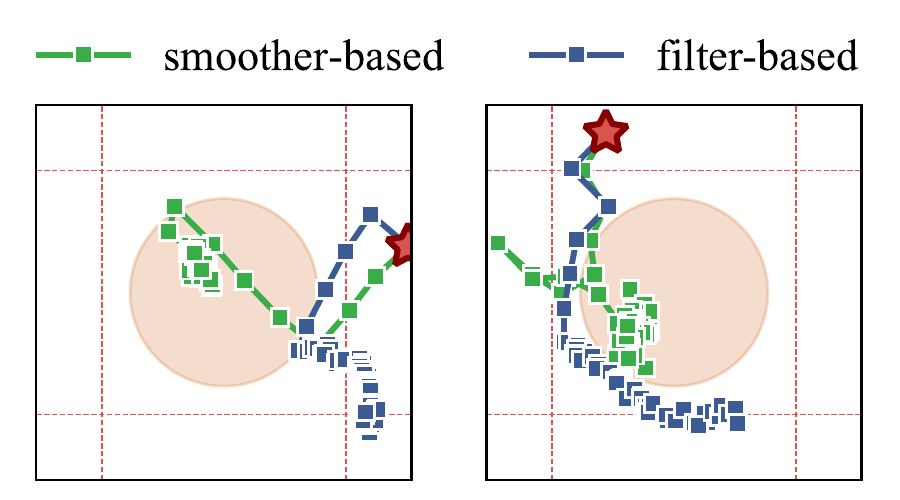
Less Suboptimal Learning and Control in Variational POMPDs How to fix model-based RL by doing the obvious.